I Tried to Invent a Better Replication Policy. It Failed.
A while ago I had a very smart-sounding distributed systems idea: older data matters less, so why are we still replicating it like it’s on fire?
The intuition felt obvious. Fresh writes matter. Cold data often doesn’t. So maybe a system should replicate aggressively at first, then back off as data ages. Less cross-AZ traffic, lower cost, acceptable consistency tradeoffs for workloads like telemetry, logs, and sessions.
That idea became Nearsight, a distributed key-value store built around what I called time-decaying consistency.
I thought I might be onto a better replication policy.
I was not.
The pitch
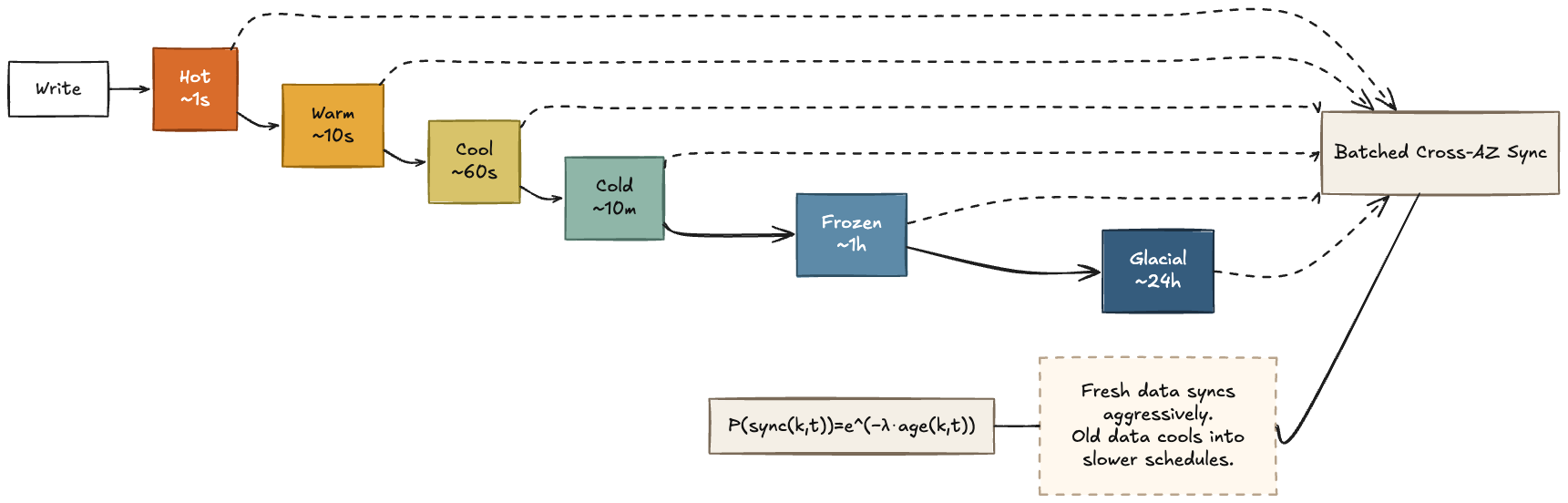
The core policy was:
\[P(\mathrm{sync}(k,t)) = e^{-\lambda \cdot \mathrm{age}(k,t)}\]In plain English: the older a key gets, the less likely it is to be synchronized across AZs at any given point in time.
So synchronization effort decays exponentially with key age. Fresh data is replicated aggressively, and old data gradually falls onto slower cross-AZ schedules.
In practice I approximated this with age buckets rather than continuously recomputing a rate for every key:
Hot: sync every ~1sWarm: sync every ~10sCool: sync every ~60sCold: sync every ~10mFrozen: sync every ~1hGlacial: sync every ~24h
Fresh writes were replicated aggressively. If a key stopped changing, it naturally cooled into slower and slower replication intervals.
Cross-AZ replication was also batched. Nodes compared age-bucketed Merkle summaries first, then only transferred divergent keys for buckets that didn’t match. So the intended effect was:
- fewer x-AZ syncs for cold data
- batched transfers instead of constant per-write chatter
- lower steady-state bandwidth for mostly cooling datasets
It sounded pretty plausible.
Which, in distributed systems, is usually when you should get worried.
So I built the thing
This did not stay at the level of a sketch.
Nearsight ended up with:
- age-bucketed replication
- Merkle-based divergence detection
- WAL, snapshots, tombstones, compaction
- hinted handoff
- topology-aware routing
- quorum/local read and write policies
- QUIC transport
- membership and failure handling
- admin APIs, audit logging, HTTPS/auth
- chaos tooling
- dashboard
- Rust client SDK
- benchmark harnesses and reports
Under the hood, I built it in Rust using in-memory storage with WAL-backed durability, HLC-style timestamps for last-write-wins conflict resolution, per-age-bucket Merkle trees for divergence detection, and QUIC for node-to-node communication. Cross-AZ sync was periodic and batched rather than write-through, with read policies ranging from local-only to quorum.
At some point this stopped being “I’m exploring an idea” and became “I guess I’m building a distributed database now.”
The good news
The good news is that the idea was real enough to implement.
A lot of distributed systems ideas die the minute they run into deletes, retries, stale reads, compaction, failure recovery, topology, or the fact that production systems are mostly unpleasant corner cases.
This one didn’t. The architecture held together. The storage layer worked. The replication logic worked. The system was coherent enough to test, benchmark, and reason about.
That alone felt like a meaningful result.
The bad news
The bad news is that “coherent enough to implement” is not the same thing as “actually better”.
In early, simple benchmark framing, the idea looked promising. But once I put together more structured benchmarking, the story changed. Nearsight did not beat the baseline on bytes sent.
That was the point where the project stopped being “I may have found something” and became “I need to understand why this lost.”
What the benchmarks actually said
This is the part that killed the original pitch.
I benchmarked nearsight_age_tiered against three alternatives in a small 2-node, 4-scenario harness: eventual_constant, bounded_staleness, and leader_hot_follower_cold. The main metric was total bytes sent.
eventual_constant was the baseline: ordinary eventual consistency with a fixed replication schedule, regardless of data age. bounded_staleness allowed more drift in exchange for lower traffic. leader_hot_follower_cold was a more asymmetric policy that favored hot-path writes and delayed colder follower sync.
Nearsight was supposed to reduce cross-AZ bytes by letting old data cool into slower replication schedules. It didn’t. In the recorded smoke benchmark, it used more bytes than the eventual_constant baseline in every scenario.
That’s the whole problem in one sentence.
The more interesting nuance is that Nearsight still kept stale-read rates very close to the baseline. So it preserved freshness reasonably well, but failed on the thing it was supposed to optimize: bandwidth.
By contrast, bounded_staleness actually did save bytes, but with noticeably worse stale-read behavior.
Overall comparison
| Policy | Avg Bytes Sent | Avg Reduction vs eventual_constant |
Avg Stale Read Rate | Avg Wall Time |
|---|---|---|---|---|
bounded_staleness |
113,425 | 45.66% | 5.65% | 0.1531s |
eventual_constant |
238,675 | baseline | 0.55% | 0.2316s |
nearsight_age_tiered |
308,412.5 | -24.00% | 0.51% | 0.2595s |
leader_hot_follower_cold |
606,741.7 | -132.95% | 3.33% | 0.1512s |
Reduction vs baseline by scenario
Positive means fewer bytes than eventual_constant. Negative means more.
| Scenario | bounded_staleness |
nearsight_age_tiered |
leader_hot_follower_cold |
|---|---|---|---|
cold_rewrite |
28.95% | -24.22% | -222.79% |
idle |
29.15% | -4.45% | 29.15% |
outage |
57.52% | -20.23% | -104.75% |
skew |
67.02% | -47.09% | -233.41% |
If I had to compress the whole experiment into one sentence, it would be this:
I built a replication policy that was nearly as fresh as the baseline, but more expensive than the baseline, which is a polite way of saying the main idea lost.
That does not make the project useless. It just makes the conclusion narrower and more honest. Nearsight did not discover a better general-purpose policy. At best, it found a point on the tradeoff curve that is more interesting than competitive.
Why this probably backfired
In hindsight, I optimized the appealing part of the system, not the whole system.
It is easy to imagine the savings from replicating cold data less. It is harder to account for everything you have to build in order to do that safely:
- bucket bookkeeping
- Merkle rebuild/compare work
- repair traffic
- recovery amplification after lag builds up
- extra coordination around cold rewrites
- skewed workloads
- outage and healing behavior
- the general cost of being clever
Distributed systems are extremely good at charging you for cleverness.
My guess is that the control plane and repair/reconciliation overhead mattered more than I expected. Once you split data into age buckets, maintain Merkle state per bucket, periodically compare summaries, reconcile divergence, and recover from lag, the savings from “sync less often” can get eaten by the machinery required to make that policy work.
So the idea wasn’t nonsense. It was just much narrower than I wanted it to be.
It may still make sense for some workload shapes. But it did not emerge as a general-purpose improvement.
The actually valuable result
Honestly, the most valuable artifact may not be the system. It may be the benchmark harness that was capable of disproving the system’s original sales pitch.
That sounds glib, but I think it matters.
A lot of systems ideas survive because nobody evaluates them hard enough to falsify them. This one did get pushed hard enough, and the result forced a correction.
So my updated view is:
- age-aware replication is a real design axis
- it is implementable
- it can help in some scenarios
- it is not automatically better
- and if you don’t measure the full system, you’re probably just telling yourself a nice story
The AI part
The other reason this project stuck with me is that I built a lot of it with AI.
Not “AI made an app for me” nonsense. More like: AI was a real implementation partner across architecture iteration, code generation, refactors, docs, tests, tooling, and benchmark scaffolding.
And weirdly, that may be the most impressive part of the whole exercise.
Because even though the main idea didn’t land, I still came away kind of amazed.
A solo person can now take a half-baked distributed systems idea and push it much farther toward “real prototype with real evidence” than would have been practical before. Not because AI guarantees good ideas. It definitely does not. If anything, this project is evidence that AI can help you build the wrong thing faster unless you stay disciplined.
AI increased my implementation speed, but it also increased the risk that a plausible idea would harden into an elaborate system before I had earned the right to believe in it.
But the leverage is real.
AI did not save me from being wrong. It did help me become wrong at a much higher level.
And I mean that as praise.
I got to build more, test more, and learn more from the same initial idea than I probably would have otherwise. That feels like a real shift in what individual builders can attempt.
Takeaway
I started out thinking I might have invented a better replication policy.
Instead I got:
- a working distributed systems prototype
- a failed headline claim
- a useful benchmark framework
- a narrower and more honest conclusion
- and a much stronger belief that AI-assisted development is opening up a new kind of technical experimentation
So no, Nearsight didn’t become the future of replication.
But I still think the experiment was a success.
Not because it proved me right.
Because it got far enough to prove me wrong.
I may open source the benchmark harness or parts of the prototype later if people are interested. Right now the write-up is the artifact I care about most.