Reliability: Finding Your Marathon Pace
The 10-second barrier, completing a 100-meter sprint in under ten seconds, once stood as the ultimate test of human speed. It was a physical and mental milestone reserved for elite sprinters. But its significance has faded since the late 1990s as more athletes have crossed the finish line in less than ten seconds. To date, 199 sprinters have officially broken this barrier. It’s impressive, but no longer impossible.
Now, consider a marathon: a 42,195-meter-long endurance test. Could a human sustain that 10-second-per-100-meter pace across such a distance? Simple math suggests a marathon at that speed would take just 1 hour, 10 minutes, and 19.5 seconds. That’s an average of 10 meters per second, or 36 kilometers per hour, maintained for more than an hour. In reality, this is far beyond human limits. The men’s marathon world record, set by Kenyan runner Kelvin Kiptum at the 2023 Chicago Marathon, is 2 hours, 0 minutes, and 35 seconds. That’s an average of 5.86 meters per second (21.1 kilometers per hour), or roughly 17 seconds per 100 meters. Even the best of the best can’t sprint a marathon.
So why are we talking about running? Because the contrast between a sprint and a marathon mirrors a critical lesson in system reliability and Service Level Objectives (SLOs). Short bursts of excellence are one thing. Sustained performance is another. SLOs require us to think beyond the finish line of a single race.
Sprinting vs. Marathon in SLOs
Think of your system as a runner. Handling a traffic spike with zero downtime is like a sprinter dominating a 100-meter dash. It’s a flashy, short-term win. But true reliability doesn’t come from one-off heroics. It comes from consistency over weeks, months, or years. That’s the marathon equivalent. Setting an SLO like 100 percent uptime might sound noble, but it’s like asking someone to sprint the entire marathon. It’s not sustainable and risks burning out both your system and your team.
Take an e-commerce platform during Black Friday as an example. A team might aim for 100 percent uptime during those 24 hours. That’s full speed, like a sprinter going for a sub-10-second run. They add servers, stay up all night, and maybe they succeed. But stretch that same level of effort across a full year, and problems begin to surface. Hardware fails. Updates cause issues. Teams get exhausted. A sprint works for a day. A marathon requires a different strategy.
Setting Realistic SLOs
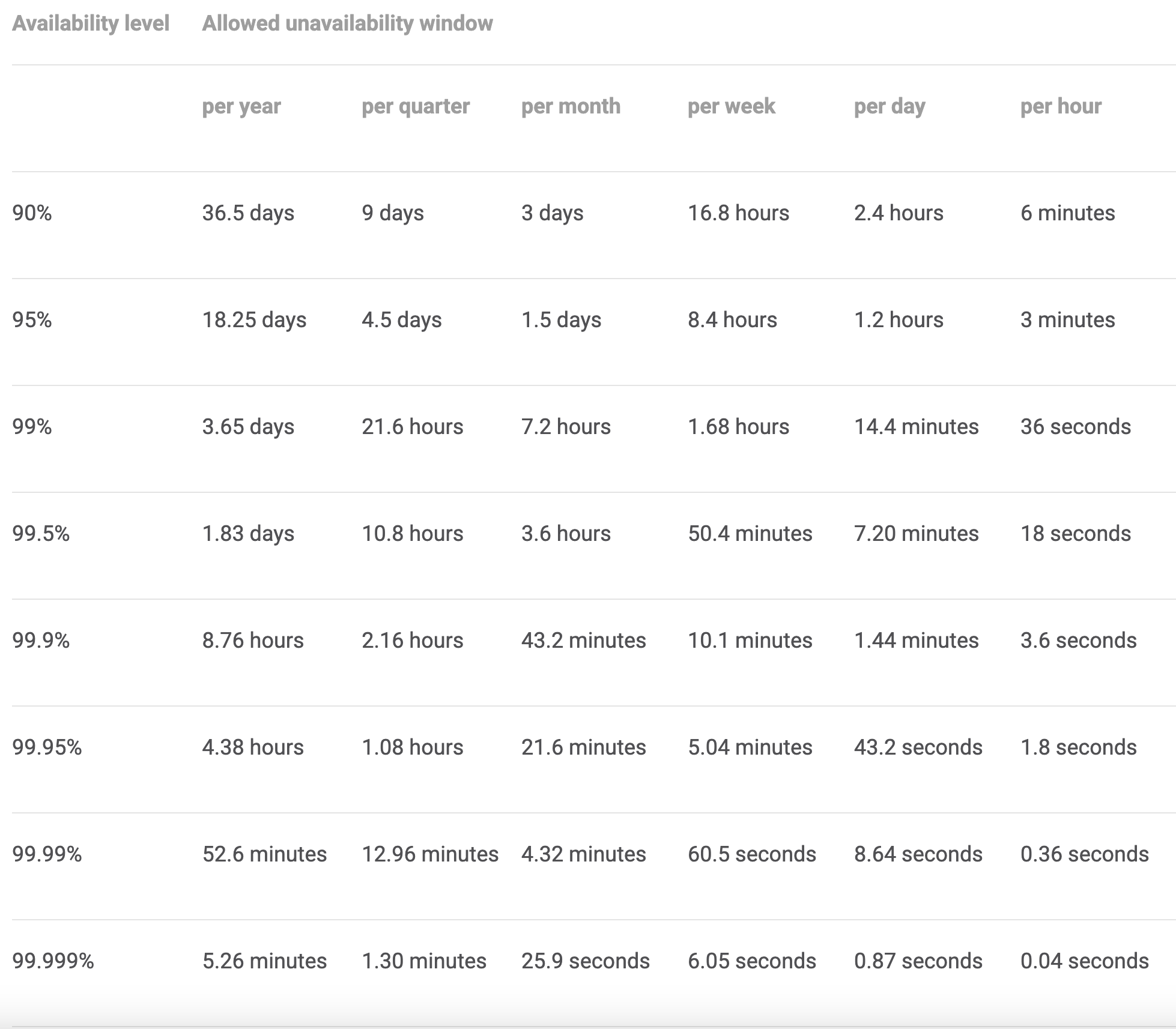
Smart SLOs take the long view. Instead of chasing perfection, aim for a goal that’s ambitious but still sustainable. A 99.9 percent uptime target, for instance, leaves room for minor hiccups. Think of them as water breaks during a marathon. Your team avoids burnout and still has energy for innovation. It’s about finding a pace that works long-term, not one that leaves everyone gasping for air.
Consider Netflix. An SLO of 99.99 percent availability for video playback sounds ideal. Users expect a smooth binge-watching experience. But that target allows only 4 minutes and 23 seconds of downtime each month. Pushing for 100 percent means expecting zero outages. That could lead to delays in rolling out new features, such as improved recommendation algorithms, to avoid any possible risk. A more practical target might be 99.9 percent. That provides around 43 minutes of downtime per month, which still ensures a great user experience while allowing the system room to breathe. The key is to align your SLO with user expectations and business goals, not a theoretical perfect score.
Now think about a healthcare app that tracks patient vitals. In this case, reliability is critical. A 99.9 percent SLO may not be enough if it means eight hours of downtime per year. A more appropriate level could be 99.99 percent, which translates to less than an hour offline annually. That still requires serious planning and investment but remains achievable with the right approach.
Balancing Performance and Reliability
Marathon runners understand the trade-off between speed and endurance. Push too hard and you’ll crash. Hold back too much and you’ll miss your goal. Systems face the same balancing act. Focusing only on peak performance can make them fragile. On the other hand, prioritizing stability too heavily might slow development to a crawl. The ideal pace combines dependable performance with long-term resilience.
Take Uber, for example. During a New Year’s Eve surge, it might achieve a 99.95 percent request success rate for a few hours. That means rides are matched quickly, delivering fast results similar to a short sprint. But applying that same target across the entire year could lead to problems. GPS issues, driver shortages, and other unpredictable factors could easily knock the system off course. A more realistic annual target might be 99.8 percent. That allows for about 17 hours of minor disruptions spread across the year. These could include delays in ride matching during peak times, while still providing a strong experience overall. If you focus only on the sprint, you might miss necessary upgrades. If you focus only on long-term reliability, you may slow innovation. The right balance keeps progress steady and systems robust.
Conclusion: Run the Right Race
When defining SLOs, don’t prepare for a 100-meter dash. Prepare for a marathon. Build systems and set goals that favor long-term reliability over short-term perfection. Whether you’re supporting an e-commerce site during a holiday rush, streaming entertainment to millions, safeguarding health data, or coordinating global transportation, the same principle applies. Match your pace to the distance. That’s how you build sustainable growth, avoid burnout, and stay in the race for the long haul.